
NOTE: this article was published on Nov 6, 2018. Things really move fast, as this EE Times article from January 2018 portrays: https://www.eetimes.com/document.asp?doc_id=1332877&_mc=sm_eet_editor_rickmerritt
The basic assumptions of the article still stand!
Artificial intelligence: everybody is talking about it, and the as-of-yet unrealized possibilities of the technology are fueling a renaissance in the hardware and software industry. Hardware and software companies — including Intel, NVidia, Google, IBM, Microsoft, Facebook, Qualcomm, ARM and many others — are racing to build the next AI hardware platform or fighting to maintain their lead.
AI, and deep learning (a sub-field of neural networks) in particular is an inherently non-Von Neumann process, and the prospect of having a processor more closely tailored to the specific needs of neural networks is appealing.
But, I like to think before acting, especially before diving into a potentially very expensive hardware project. And I would like to follow the very same paradigm that deep learning successfully uses to compute — learn from past examples — to determine the best path forward when considering this important question:
Should the AI industry build a specialized deep learning chip, and, if so, what should it look like?
Let’s first look at the past to predict the future.
The World Is Administered by the Wise but Progresses Because of the Crazy
The U.S. Defense Advanced Research Projects Agency (DARPA) is an agency created in 1958 as the Advanced Research Projects Agency (ARPA) by U.S. President Dwight Eisenhower with the goal of the developing “crazy innovative” technologies for use by the military. The agencies played a vital role in the development of defense (and non-defense) technology, such as ARPANET, the basis for what would become the internet; GPS technology; and many others.
In 2008, DARPA launched the Systems of Neuromorphic Adaptive Plastic Scalable Electronics (SyNAPSE). The goal was to create a new breed of non-traditional brain-inspired processors that could perform perception and behavioral tasks while simultaneously achieving significant energy savings.
Biology makes no distinction between memory and computation.
The program, which originally involved my lab at Boston University and researchers at Hewlett-Packard, HRL Laboratories, and IBM, had the goal of achieving energy efficiency by intelligently locating data and computation on the chip, alleviating the need to move data over large distances. The idea was to do this from a single synapse and scale up to a whole brain (see figure).
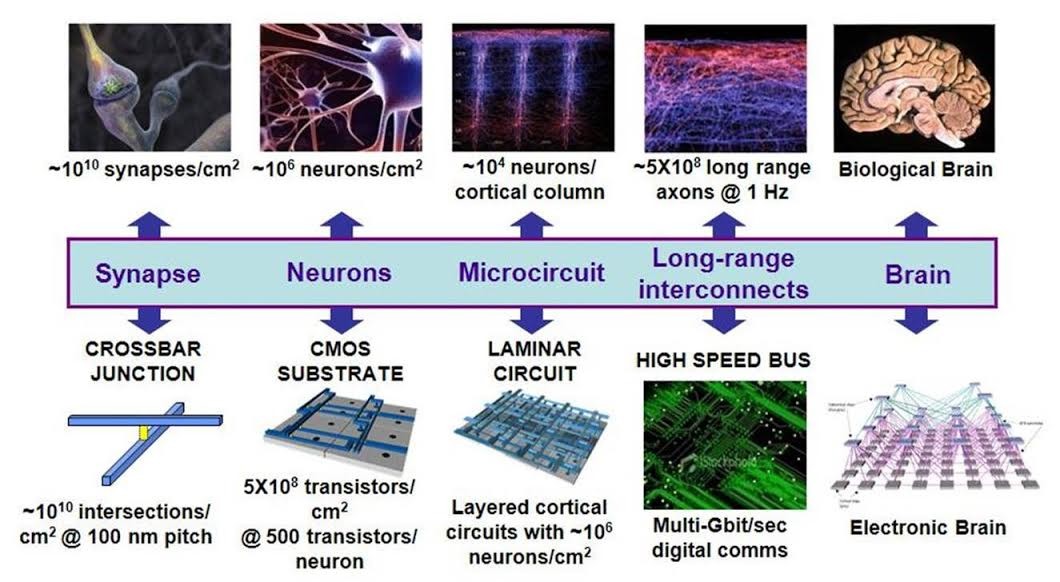
 Some versions of the chip employed sophisticated memristive device technologies to implement dense connectivity between neurons and asynchronous computation — processing and transmitting data only as required, similar to how neurons process and communicate information.
Some versions of the chip employed sophisticated memristive device technologies to implement dense connectivity between neurons and asynchronous computation — processing and transmitting data only as required, similar to how neurons process and communicate information.Why SyNAPSE?
SyNAPSE was a complex, multi-faceted project, but it was rooted in two fundamental problems. First, traditional algorithms perform poorly in the complex, real-world environments in which biological agents thrive. Biological computation, in contrast, is highly distributed and deeply data-intensive. Second, traditional microprocessors are extremely inefficient at executing highly distributed, data-intensive algorithms. SyNAPSE sought both to advance the state-of-the-art in biological algorithms and to develop a new generation of nanotechnology necessary for the efficient implementation of those algorithms.
 Biology makes no distinction between memory and computation. Virtually every synapse of every neuron simultaneously stores information and uses this information to compute. Standard computers, in contrast, separate memory and processing into two nice, neat boxes. Biological computation assumes these boxes are the same thing. Understanding why this assumption is such a problem requires stepping back to the core design principles of digital computers.
Biology makes no distinction between memory and computation. Virtually every synapse of every neuron simultaneously stores information and uses this information to compute. Standard computers, in contrast, separate memory and processing into two nice, neat boxes. Biological computation assumes these boxes are the same thing. Understanding why this assumption is such a problem requires stepping back to the core design principles of digital computers. The vast majority of current-generation computing devices are based on the Von Neumann architecture. This core architecture is wonderfully generic and multi-purpose, attributes which enabled the information age. Von Neumann architecture comes with a deep, fundamental limit, however. A Von Neumann processor can execute an arbitrary sequence of instructions on arbitrary data, enabling re-programmability, but the instructions and data must flow over a limited capacity bus, connecting the processor and main memory. Thus, the processor cannot execute a program faster than it can fetch instructions and data from memory. This limit is known as the “Von Neumann bottleneck.”
The vast majority of current-generation computing devices are based on the Von Neumann architecture. This core architecture is wonderfully generic and multi-purpose, attributes which enabled the information age. Von Neumann architecture comes with a deep, fundamental limit, however. A Von Neumann processor can execute an arbitrary sequence of instructions on arbitrary data, enabling re-programmability, but the instructions and data must flow over a limited capacity bus, connecting the processor and main memory. Thus, the processor cannot execute a program faster than it can fetch instructions and data from memory. This limit is known as the “Von Neumann bottleneck.”
Multi-core and massively multi-core architectures are partial solutions but still fit within the same general theme. Extra transistors are swapped for higher performance. Rather than relying on automatic mechanisms alone, though, multi-core chips give programmers much more direct control of the hardware. This works beautifully for many classes of algorithms, but not all and certainly not for data-intensive bus-limited ones.
Unfortunately, the exponential transistor density growth curve cannot continue forever without hitting basic physical limits, and these transistors will not serve the purpose of enabling brains to run efficiently in silicon. Enter the DARPA SyNAPSE program.
The Outcome of SyNAPSE
In 2014, after about six years of effort, one of the groups — IBM in San Jose, California — announced the “birth” of its SyNAPSE chip, loaded with more than five billion transistors and more than 250 million synapses (programmable logic points). The chip was built on Samsung Foundry’s 28nm process technology, and its power consumption was less than 100 milliwatts during operation. Despite this still being orders of magnitude fewer than the actual count of brain synapses, it was an important step toward building more brain-like chips.


So, after DARPA poured tens of millions of dollars into SyNAPSE, where are neuromorphic—“brain-inspired”—chips today? Can I find them at Best Buy, as I can find the other processors used today to run AI?
They are nowhere to be found.
So, what can be found? Which hardware can AI run on?
CPU, GPU, VPU, TPU, [whatever you want]PU
While you can’t buy a fancy SyNAPSE processor to run your AI, you have surely heard of — and maybe have even bought — CPUs or GPUs (graphics processors). GPU-accelerated computing leverages GPUs to reduce the time in computing complex applications: it offloads compute-intensive portions of the application to the GPU, while the remainder of the code still runs on the CPU. An intuitive way to understand why this is faster is to look into how CPUs and GPUs compute: while CPUs are designed to have a few cores optimized for sequential serial processing, GPUs have been built by design as massively parallel processors consisting of thousands of smaller cores which are best at handling multiple tasks simultaneously.
Movidius, now part of Intel (as the FPGA company Altera and the AI hardware company Nervana), built and successfully commercialized a Visual Processing Unit (VPU). VPUs differ from GPUs as they were designed from the ground up to allow mobile devices to process intensive computer vision algorithms (whereas GPUs were adapted from processing graphics to machine vision).
Aside from NVidia (GPUs) and Intel (CPUs and VPUs), Google has joined the battle with the Tensor Processing Unit (TPU). This is a custom ASIC specifically built for Google’s TensorFlow framework. The energy/speed savings are achieved by being more lenient to compute precision losses: by allowing the chip to be more tolerant of reduced computational precision, the TPU requires fewer transistors per operation. Since neural networks can tolerate such a precision loss by gracefully degrading performance (rather than “STOP WORKING”), it’s a processor that simply works.
How about Qualcomm? The company has talked up, and then apparently abandoned, its Zeroth AI software platform for mobile computing, but it’s hard to get a clear sense of Qualcomm’s efforts in this area, although recent efforts on Snapdragon seem to indicate a resurgence of interest.
Finally, we should not forget ARM: the chip-licensing firm — whose claim to fame is low-power processing — is heavily researching and investing in AI. And, to be honest, we can run Neurala’s algorithms pretty well on those tiny and inexpensive chips already!
So, there is plenty of hardware available to run your AI. What is the common thread of this hardware, and is it the time for the hardware industry to jump into another “specialized AI chip?”
3 Lessons Learned from Brain-Inspired Hardware
Programmability, programmability, programmability.
The success of NVidia is only partially due to performance. There are alternatives to NVidia processors that are either faster, leaner in power requirements or both. But NVidia’s sweet spot is a judicious intersection of performance, price and ease of use. The company has done a very good job of making the development, testing and fielding of neural network algorithms seamless.
So, why is programmability so important for AI?
Because AI is still a very young and dynamic field. Neural networks, deep learning and reinforcement learning: these are all research-intensive enterprises. In research, flexibility and ease of use are key to shortening the time for a research cycle. A new paradigm or a new variation in an AI algorithm may modify the underlying mathematical and computational assumptions enough to make any specialized hardware hopelessly obsolete.
I truly believe that, in the best interest of advancing AI, hardware and software should be somehow factorized, as to allow maximum flexibility to algorithm developers, in particular at a time when AI is quickly innovating and finding its path.
I believe that the hardware company that understands this trend and provides flexibility as the first and foremost feature will succeed in capturing the heart — and brains — of the field.