
One of the questions we I often get in working with AI is:
“Cool… I see this AI never stops learning. But it’s like Transfer Learning, right?…”
Although people are uttering words like Deep Leaning, Neural Networks, Transfer Learning with the same ease they order a latte at Starbucks, I am less confident that they truly understand the subtle, but crucial differences in these algorithms. So crucial as the distinction between Newtonian and Relativistic physics, which to be proven had to be initially tested on subtle diffraction of light from Sun eclipses and the orbit of Mercury, but whose radical difference and ramifications are simply immense.
Similarly immense is the divide between Continual Learning and traditional DNN learning.
Me and my colleague have spent years studying and implementing Lifelong DNN (or L-DNN), today a well-developed, deployed family of networks belonging to the nascent category of ‘continual learning’ algorithms. How do they differ from traditional “AI” (better, DNN… or Deep Neural Networks) algorithms?
First off, let’s remind everybody how today’s Deep Neural Networks work. Then, I will clear up your mind once and for all. Can’t wait!…
How today’s DNN work
Based on theoretical work from the 1960s, today’s Deep Learning and neural network algorithms derive their power from the ability to learn from the data (vs. being preprogrammed to perform a function).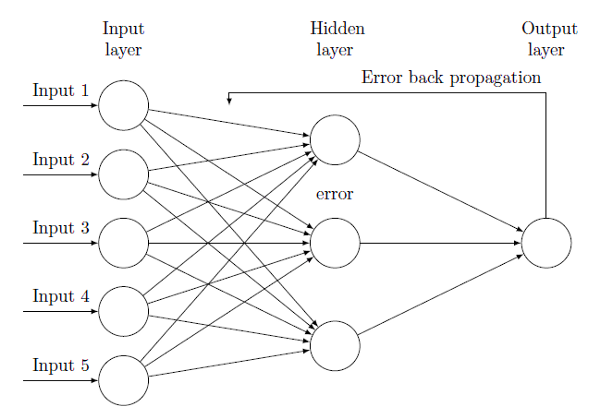
They also overwhelmingly use a learning formalism crystallized in the 1980s: Backpropagation. This algorithm optimizes the network output by iteratively adjusting the weight of each neuron, completing the learning process for that piece of data (e.g., an image). This enables AI systems based on Backpropagation to match and sometimes surpass human-level performance in an ever-increasing list of tasks, from playing chess to detecting an intruder in a security camera.
However, this super-performance comes at some heavy price: Backpropagation networks are very sensitive to new information and are susceptible to catastrophic interference. When something new is learned, it wipes out old information. To mitigate this problem, researchers took two steps:
1. Make learning slower by changing synapses by only a small amount and repeating the process over many iterations, typically many hundreds of thousands or millions, where each input is presented repeatedly and its error continuously reduced, a little at a time.
2. Simply freeze learning after the target performance is reached to avoid compromising older information learned when new information is added.
So, today’s DNN are slow to train and static after training (because updating them is glacially slow). Shocked? Wait until I tell you about Transfer Learning.
How about Transfer Learning?
Now, what is this Transfer Learning (TL) thing and how does it compare?
TL is today a pretty popular approach where a previously developed DNN is ‘recycled’ as the starting point a DNN that learns a second task.
Demystifying what this means: it’s using some pretrained weights to initialize a new DNN which helps a bit….
Basically, NOTHING really changes with respect to a traditional DNN methodology, except you can train on less data….
 For example, if you have a model that was trained on the popular Imagenet which can recognize 1000 object classes (cars, dogs, cats, etc), and say you want to train a new model on telling apart the hybrid Yucatan/Siberian Armadillo and the new Tasmanian pterohyppopotamus (I hope these are rare animals…) your grandma has in her yard, TL would try to learn these two animals by initializing a new network with the weights from the bigger 1000 class network which already knows a bit about what animals look like.
For example, if you have a model that was trained on the popular Imagenet which can recognize 1000 object classes (cars, dogs, cats, etc), and say you want to train a new model on telling apart the hybrid Yucatan/Siberian Armadillo and the new Tasmanian pterohyppopotamus (I hope these are rare animals…) your grandma has in her yard, TL would try to learn these two animals by initializing a new network with the weights from the bigger 1000 class network which already knows a bit about what animals look like.
While TL may help in making the training of the new network faster and more reliable in general, a catch is that the newer network can NOW ONLY RECOGNIZE Yucatan/Siberian Armadillo and Tasmanian pterohyppopotamus.
Two things. Not 1,002!
Let me restate it: the new network does not know anything about the 1,000 objects you previously learned, it can ONLY recognize the 2 new ones.
So, even though this training would be faster than your training sessions initialized from scratch, it could still take anywhere from hours to days, depending on the size of the dataset. Remember, all DNN-like issues described above apply.
TRANSFER LEARNING IS NOT A NEW METHOD FOR DEEP LEARNING. YOU JUST TRAIN ON LESS USING A RECYCLED NETWORK.
While recycling is good for the environment, it’s not revolutionary for AI.
Then, how about L-DNN?
Lifelong-DNN (L-DNN) is inspired by brain neurophysiology and mimics in software the ability of cortical and subcortical circuits to work “in tandem” to add new information on the fly. While DNN, as described above, train in a iterative manner over large datasets for the reason highlighted, L-DNN uses an completely different methodology in learning, where iterative process are mathematically approximated by instantaneous ones, in an architecture that introduces new processes, layers, and dynamics with respect to traditional DNNs.

Crucially, with L-DNN, you pay a constant price in training: namely, you only train once on every piece of data you encounter. This translates in massive gains in training speed, where, on the same hardware, L-DNN can train between 10K to 50K faster than a traditional DNN.
 So, how about Yucatan/Siberian Armadillo and its Tasmanian pterohyppopotamus friend?
So, how about Yucatan/Siberian Armadillo and its Tasmanian pterohyppopotamus friend?
L-DNN would let train on animal species (say, 10 of them) and will then let you add the two new animal species category to the already existing class network with just milliseconds of training and so now your grandma has a network to tell apart her exotic animals.
If you tried to do so with TL, even after initializing the new 12-class model with the old 10-class model’s weights, you will still have to train it for days and would need more data than L-DNN would.
Even worse: since TL is exactly like DNN training, you will need to preserve ALL TRAINING DATA, since DNN training iterates over all data points. With L-DNN, you can just keep adding new stuff on top of old stuff with just new data, you do not need the images of those 10 animal classes you had earlier anymore.
That’s huge… namely, with L-DNN you can throw away learning data, whereas with DNN you need to keep it. Just imagine the implication in terms of privacy!
(want to learn more about lifelong learning? See here)
Summary: Transfer Learning vs. L-DNN
Now you got it. You are enlightened. You will never confuse the old (DNN) with the new and improved (L-DNN and Continual Learning). Steam engines were good, but now there are electric ones.
So, to summarize one more time:
 · Although one can get a faster training than traditional DNN, training is still slow, non-instantaneous, and non-incremental;
· Although one can get a faster training than traditional DNN, training is still slow, non-instantaneous, and non-incremental;
· You need to add 1 new piece of data to your network that already knows 1,000? Transfer Learning has no answer for that other than train on 1,001 data points. With L-DNN, you pay a constant, negligible price, and you train on 1 piece of data only.
· With L-DNN, you do not need to preserve all your training data. With DNN, if you don’t, you are finished.
Please never ever confuse the novel L-DNN learning paradigm with traditional DNN training, either in its original form, or in its new incarnation TL.